EventMachine for Syncroholics®
I like to keep track of Dressage scores published by usdf.org. USDF has records of about 1.5 million individual rides going back almost 20 years. This is an opportunity for Dressage geeks to engage in Sabermetrics like analysis of horses and riders.
Being a syncroholic, my first solution to the problem of getting the data onto local storage for analysis is predictably syncronous:
#!/usr/bin/env bash
base_url="http://www.usdf.org/calendar/results.asp?CompetitionPass="
for id in {2..20000} ; do
wget --quiet -O "pages/$id".html "$base_url$id"
done
While this works, it takes a while. About 11 hours on a well connected host (2 seconds per wget).
USDF.org publishes a page for each horse show identified by a unique id (url), each show page records from 5 to 1000 rides, depending on the size of the horse show. About half of the ids in the sequence between 2 and 20000 don’t contain any ride data at all, the empty pages take just as long to get as the populated ones.
At the September meeting of the Spokane RUG, Chris Reister gave a presentation on EventMachine.
Inspired by Chris' presentation, I did some experiments to see how much faster concurrent http gets would be for getting show results pages from usdf.org.
Here’s a chart showing the results of 10 trials getting 100 random pages with “FiberIterator” concurrency varying between 1 and 20:
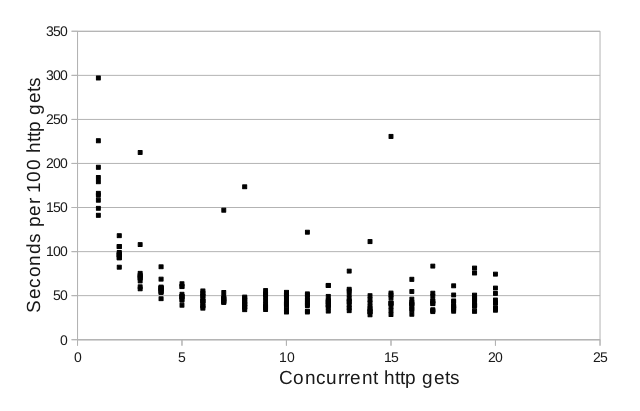
The chart tells me what I need to know: setting concurrency greater than 5 (5 parallel get requests) does not improve performance.
I used Ilya Grigorik’s em-synchrony gem so I don’t have to explicity handle EventMachine callbacks.
require "em-synchrony"
require "em-synchrony/em-http"
require "em-synchrony/fiber_iterator"
BASE_URL="http://www.usdf.org/calendar/results.asp?CompetitionPass="
SCORES=/<div id="sub-content">.*<\/div>/m
AFTER_SCORES=/<div id="footer">.*<\/div>/m
NO_RESULTS=/There are no results at this time/
HTTP_SUCCESS=200
CONCURENCY=5
urls = (2..20000).map{|id|BASE_URL+"#{id}"}
def save_page(resp,url)
if resp.response_header.status == HTTP_SUCCESS
unless resp.response =~ NO_RESULTS
File.open("pages/#{url[/\d+$/]}.html", 'w') do |f|
f.write(resp.response.match(SCORES).
to_s.gsub(AFTER_SCORES,''))
end
end
else
puts "#{url} #{resp.response_header.status}"
end
end
EM.synchrony do
EM::Synchrony::FiberIterator.new(urls, CONCURENCY).each do |url|
resp = EventMachine::HttpRequest.new(url).get
save_page(resp,url)
end
EventMachine.stop
end
The Ruby save_page() method saves only pages containing data and then only the html div that contains relevent results.
Using 5 concurrent gets, is about 4 times faster than the one page at a time method. That’s about 2.75 hours versus 11 hours to get 20,000 pages.
Now I can get all the pages in the middle of the night while the human users of usdf.org sleep.
Hello, my name is George, and I am a (Recovering, thanks to EventMachine) Syncroholic.
